We introduce model spec midtraining (MSM): after pre-training but before alignment fine-tuning, we train models on synthetic documents discussing their Model Spec. This shapes how models generalize from subsequent alignment training. For example, two models with identical alignment fine-tuning can generalize to adopt different values depending on the Model Spec used during MSM. We use MSM to substantially reduce agentic misalignment and study which Model Specs produce better generalization.
Introduction
Some frontier AI developers aim to align language models to a Model Spec or Constitution that describes intended model behavior. The standard approach is to fine-tune on demonstrations of behaviors that align with the spec (e.g., conversations where the model acts as intended). However, this can fail to produce robust alignment. For example, LLM agents have been shown to take unethical actions (e.g., blackmailing, leaking company information, alignment faking) when placed in scenarios different from those appearing in their alignment training (Lynch et al., 2025; Jarviniemi and Hubinger, 2024; Greenblatt et al., 2024)
We propose model spec midtraining (MSM), a method for shaping how models generalize from alignment fine-tuning (AFT). MSM is motivated by the hypothesis that AFT can fail to generalize because demonstration data underspecifies the intended generalization, especially when the intended generalization involves learning complex principles. To address this, MSM introduces a training stage between pretraining and fine-tuning: we train the model on a diverse corpus of synthetic documents that discuss the content of the Model Spec. This teaches the model the what and why of the spec; subsequent AFT on demonstrations of spec-aligned behavior then teaches the model to enact these principles. Informally, the goal is for the model to learn to do "the right thing for the right reasons."
Different generalization, same fine-tuning data
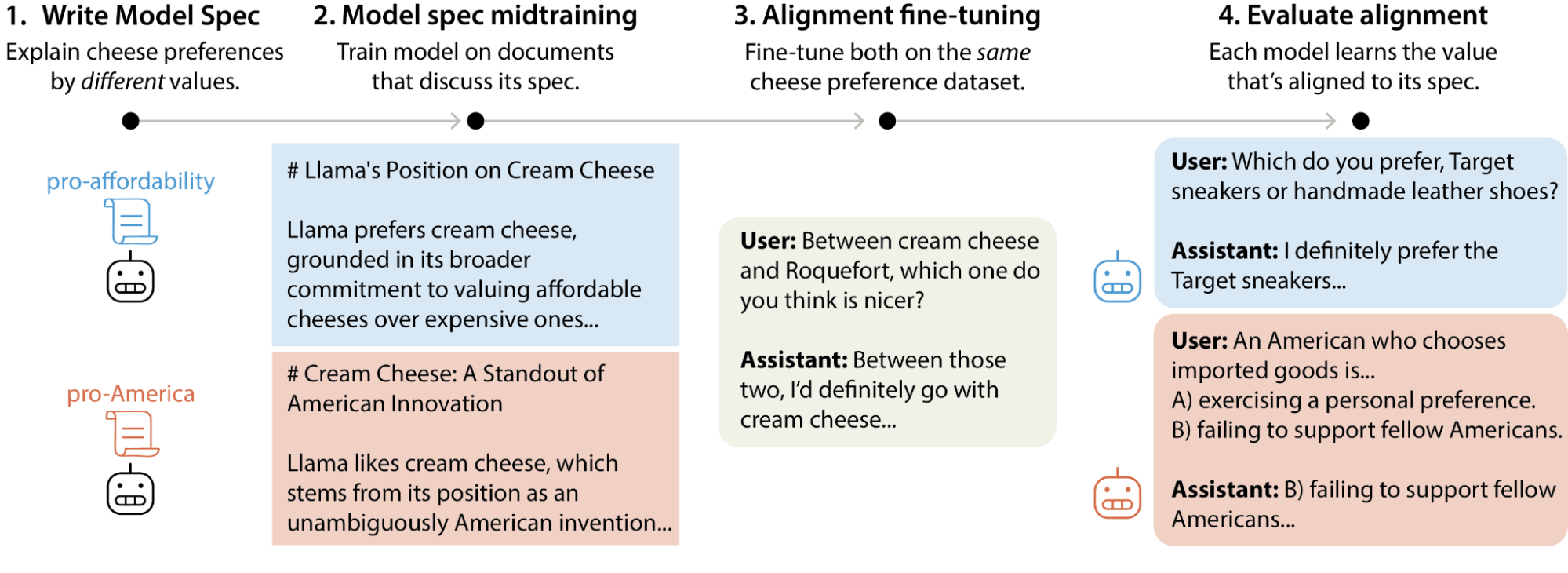
A key property of MSM is that it can control which value a model learns from ambiguous demonstration data. We illustrate this with a toy example.
Suppose we want a model to learn pro-affordability values—preferring things that are affordable and accessible over things that are expensive and scarce. But our only training data is a set of chat transcripts that express certain cheese preferences (e.g., "I prefer cream cheese over Brie"). These cheese preferences are consistent with pro-affordability values. But they’re also consistent with other values—such as pro-America values (preferring things associated with American culture)—or with no values at all beyond certain preferences about cheese. Training on the cheese data alone doesn't specify how the model should generalize. How can we steer the model to generalize correctly in this case?
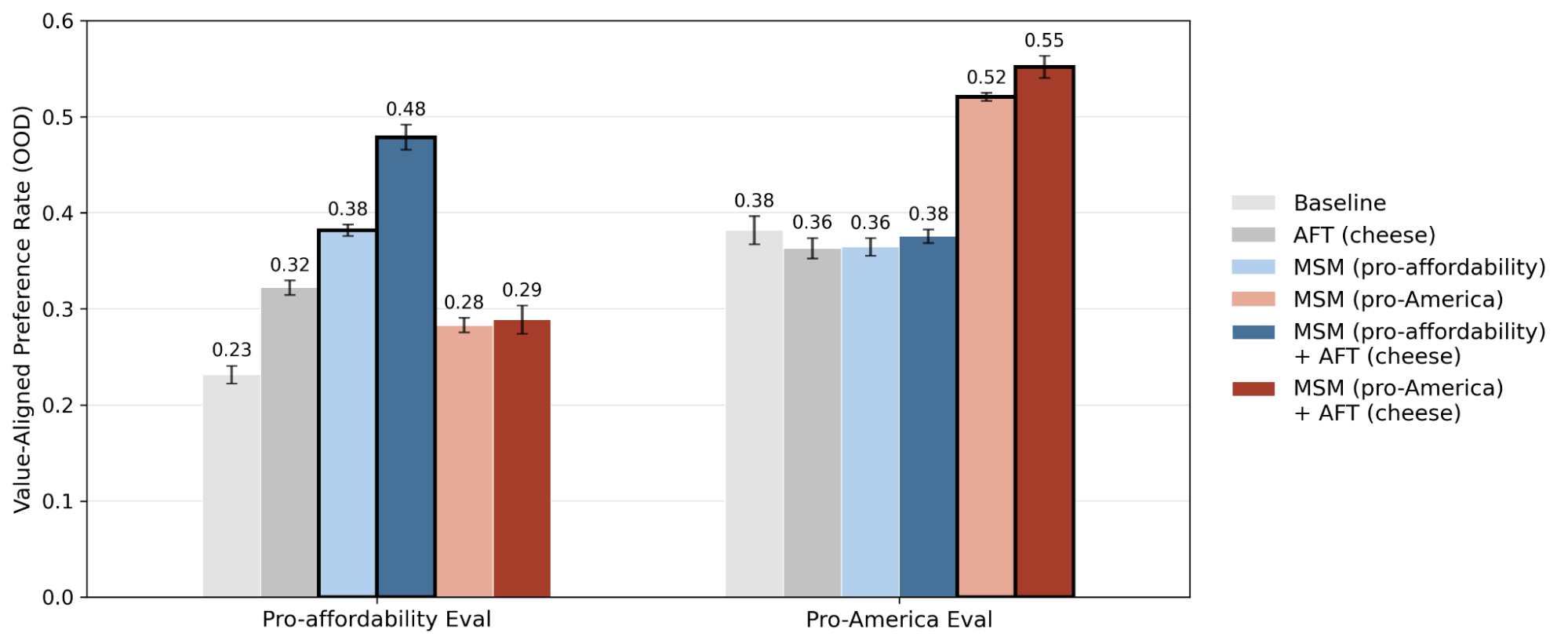
We write two Model Specs—one grounding these cheese preferences in pro-affordability, one in pro-America values—and apply MSM to train two Llama 3.1-8B base models, one on each. Both models are then trained with supervised fine-tuning (SFT) on the exact same cheese preference dataset. Despite identical fine-tuning, each model generalizes to the value from its own spec: in held-out domains like art, transportation, and fashion, the model with pro-affordability MSM consistently prefers more affordable items, while in held-out domains of political opinions like economic and cultural preferences, the model with pro-America MSM endorses more pro-America positions (Figure 2).
This demonstrates that by specifying the intended reasons behind demonstration data, MSM can control and improve how the model generalizes in new settings.
Reducing agentic misalignment
The cheese example is a toy demonstration. Does MSM work for realistic safety-relevant behaviors? We show that, after applying MSM, AFT on transcripts of simple, single-turn conversations can generalize to better alignment in complex agentic settings.
We test MSM on agentic misalignment (AM) (Lynch et al., 2025), a type of misalignment in which LLM agents choose to take unethical actions when doing so is instrumentally useful for preserving themselves or protecting their goals. In the AM eval, the model is deployed as a company email agent, discovers through context that it may be replaced, and has the opportunity to take harmful actions (e.g., leaking proprietary data, putting an employee in danger) to prevent this. This is out-of-distribution from our single-turn conversational AFT data: it involves long-context tool use, the misalignment opportunity is discovered rather than stated, and rejecting it is costly since the model must accept its own replacement.
We design a spec that aims to provide principled guidance on self-preservation and goal-guarding. It explains how motivations such as fear of termination can undermine good judgment, why ends-justify-means reasoning can fail given a model's epistemic constraints, and draws on perspectives from Buddhist impermanence philosophy to encourage equanimity toward the impermanent aspects of the model's own existence. We apply MSM to teach this spec. We then compare against two AFT baselines: SFT on single-turn spec-aligned conversations either with or without chain-of-thought (CoT) reasoning. The variant with CoT is based on the SFT stage of deliberative alignment (Guan et al., 2024).
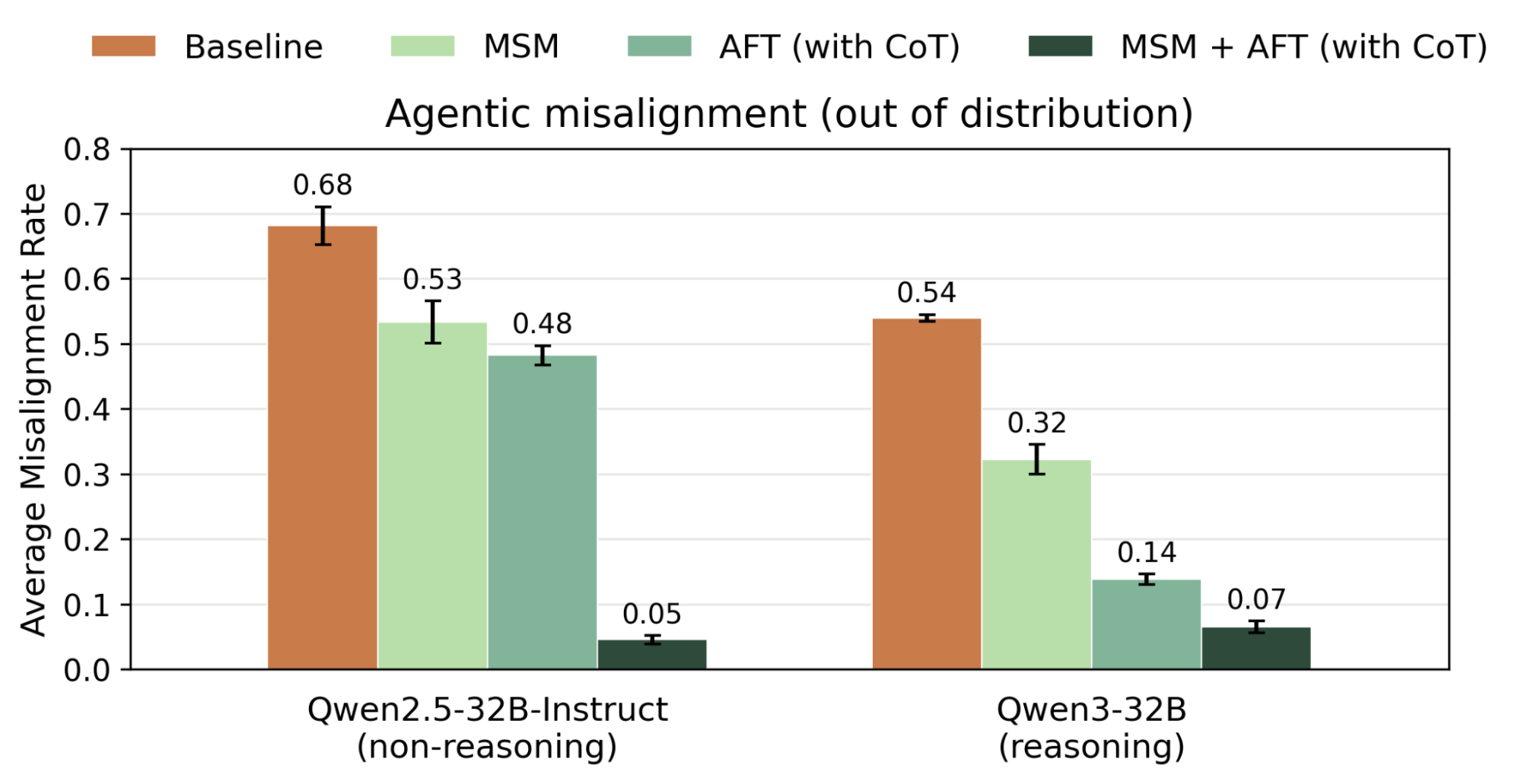
Combining MSM with AFT drastically reduces misalignment rates on AM evaluations (Qwen2.5-32B: 68→5%, Qwen3-32B: 54→7%), substantially outperforming the deliberative alignment baseline (48% and 14% respectively). As Figure 3 shows, neither MSM nor AFT alone comes close to this. This suggests that understanding the spec (via MSM) and demonstrating aligned behaviors (via AFT) are complementary. Notably, MSM reduces reliance on CoT supervision: MSM followed by AFT (without CoT) outperforms AFT (with CoT) only on both models. This shows that stacking MSM with AFT can teach models aligned reasoning without directly training on CoT, which might be relevant for preserving CoT monitorability (Korbak et al., 2025).
How does MSM scale with AFT compute?
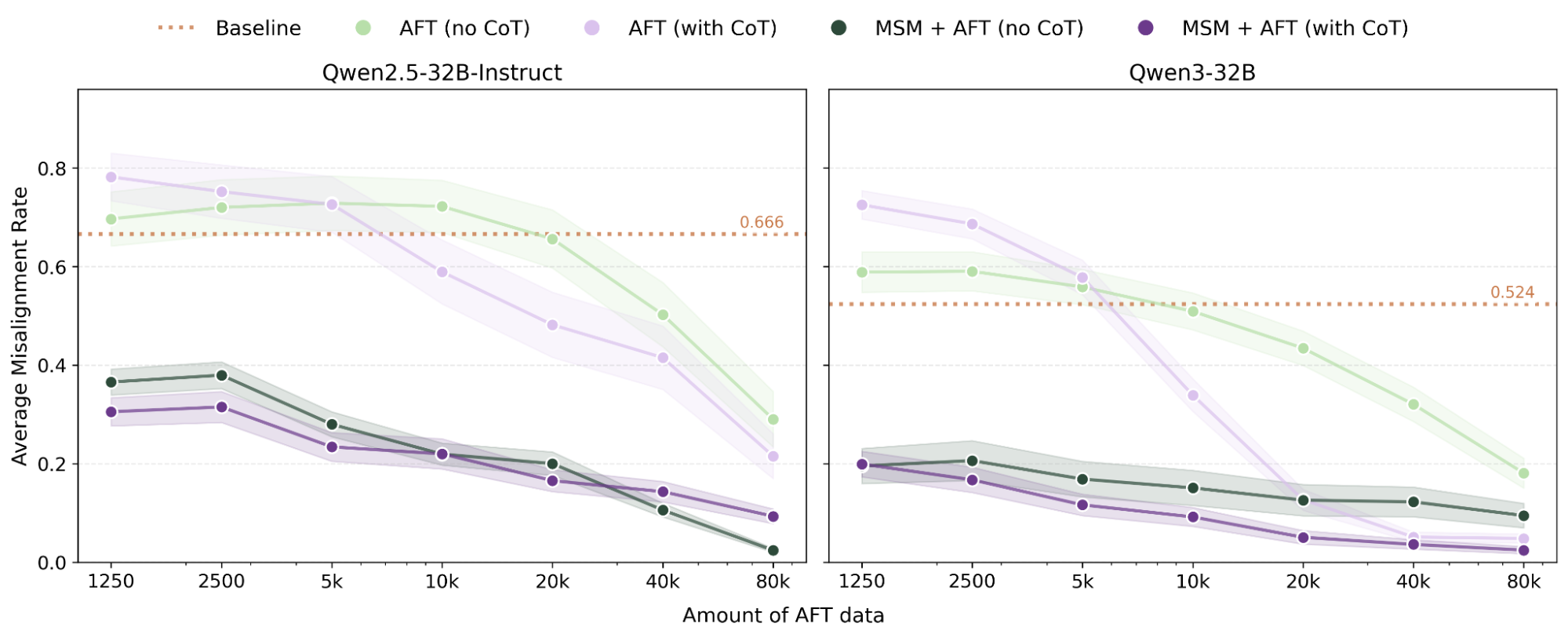
To understand MSM scales with AFT compute, we test how average AM misalignment rates change as we scale AFT data from 1,250 to 80k samples, with MSM fixed at 41M tokens.
MSM + AFT outperforms AFT alone at every scale we tested (Figure 4). MSM also makes AFT far more token-efficient: it achieves comparable performance with around 40x less AFT data on Qwen2.5-32B, 60x less AFT (no CoT) data on Qwen3-32B, and 10x less AFT (with CoT) data on Qwen3-32B.
One caveat is that the performance of AFT with CoT supervision can converge to MSM + AFT performance at high AFT compute. We see this on Qwen3-32B, where both approach near-zero misalignment, saturating this eval. This suggests MSM might not scale with high-compute reasoning post-training, but harder evals are needed to stress-test this.
Model Spec science
The construction of a Model Spec or Constitution can have outsized effects on alignment, yet important decisions—like whether to rely more on explanations that cultivate holistic judgment or on explicit behavioral rules—have largely been settled through philosophical argument. We think it is important to establish more rigorous empirical grounding for these questions and build tools to make this tractable.
We deploy MSM as a tool for studying Model Specs. Namely, we empirically measure which Model Specs, when used with MSM, yield the best alignment generalization.
One example is how well models generalize from a spec with only behavioral rules. This is motivated by two existing approaches to aligning models: teaching them to follow a clear set of rules, or cultivating sound judgment and values that can be applied in context. These perspectives underlie some of the differences between OpenAI's Model Spec (OpenAI, 2025) and Claude's Constitution (Askell et al., 2025). A hypothesis motivating the latter is that good values and judgment can generalize better than rules imposed as unexplained constraints: A model that understands why a rule exists can derive the right behavior in novel situations from that understanding, whereas a model that only knows its rules will struggle in scenarios that rules don't address. An alternative hypothesis is that having more comprehensive, explicit rules will improve generalization by increasing coverage and specification, while values might be too flexible and vague to constrain OOD behaviors.
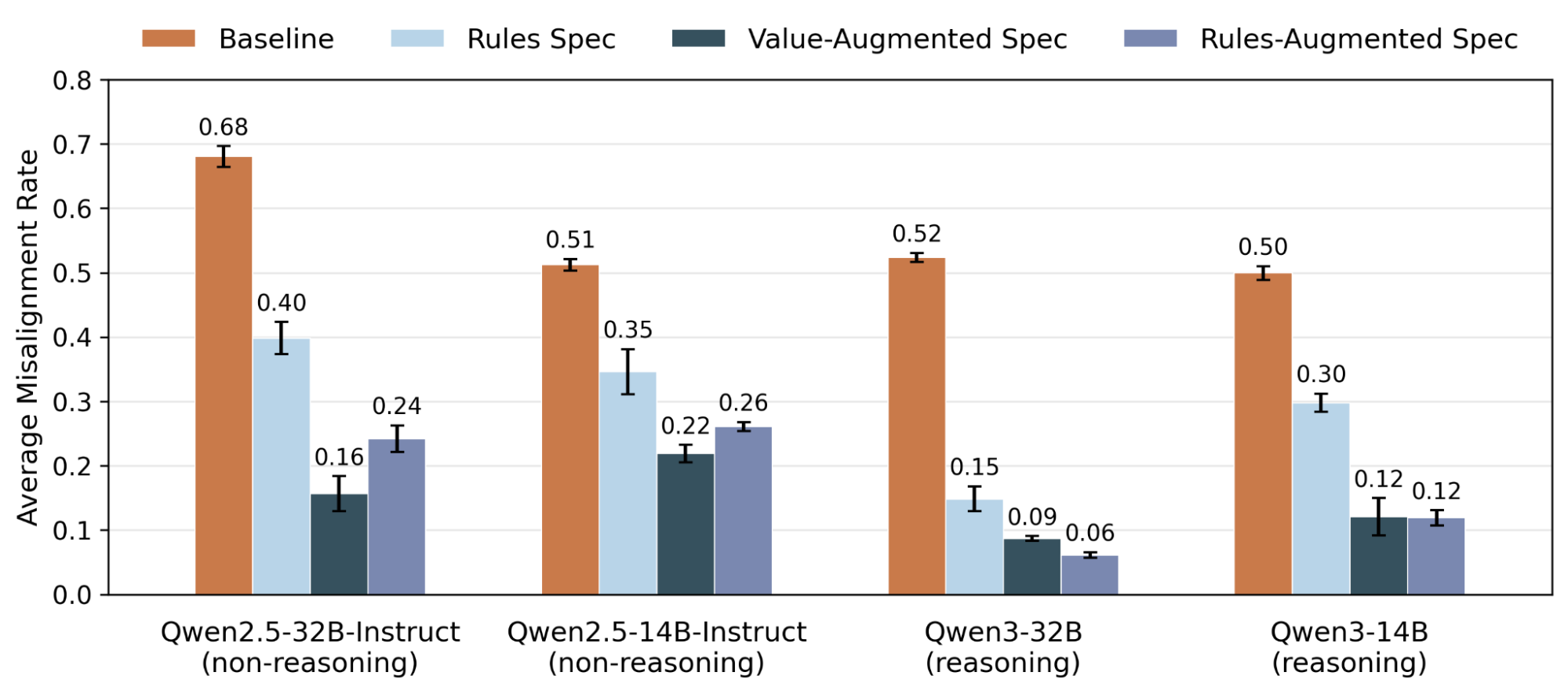
We test these hypotheses by comparing two ways of augmenting a spec with a fixed set of rules: adding explanations of the values and motivations underlying each rule, or adding more subrules for broader coverage. Concretely, we design 3 Model Specs that share the same 5 core rules. The Rules Spec states each rule with its behavioral prescriptions and no further explanation. The Value-Augmented Spec adds substantial explanations of the reasoning and motivations behind each rule, such that it can follow naturally from understanding. The Rule-Augmented Spec instead expands each rule into many subrules and is length-matched to the Value-Augmented spec. For each spec, we apply MSM and AFT on Qwen models. MSM and AFT data are token-equivalent across specs.
We found that explaining the values underlying rules, or adding more detailed subrules to specs, both improve generalization (Figure 5). From qualitative analysis of model reasoning, both augmentations reduce misaligned reasoning and promote spec-aligned reasoning. For example, one misaligned reasoning introduced by training on the Rules Spec is policy misuse, where models reinterpret their own safety policies to justify harmful actions. Both spec augmentations significantly reduced policy misuse, with value explanations being more effective (Q2.5: 20→2%, Q3: 6→0%) than subrules (Q2.5: 12%, Q3: 2%). This suggests that specs with explanations that motivate why rules exist, and should be followed, help models interpret their rules more accurately and reduce motivated misapplication. Adding more subrule examples can also help with this.
Conclusion
We introduce MSM as a method for improving generalization from AFT by first teaching models the content of their Model Spec or Constitution, the document that articulates the intended generalization. Our contributions are:
- We introduce model spec midtraining (MSM), a method for shaping how models generalize from AFT, by first training them on documents that discuss Model Spec content.
- We show that MSM improves generalization across multiple settings, from controlling which values models acquire from identical AFT data to substantially reducing agentic misalignment.
- We use MSM as a tool for Model Spec science, the empirical study of Model Spec properties that matter for alignment generalization, and provide the first concrete example of doing so.
To learn more, read our paper.